So I will just try to explain GMM and the consumption estimates, the work most prominently featured in the Nobel citation. Like all of Lars' work, it looks complex at the outset, but once you see what he did, it is actually brilliant in its simplicity.
The GMM approach basically says, anything you want to do in statistical analysis or econometrics can be written as taking an average.
For example, consider the canonical consumption-based asset pricing model, which is where he and Ken Singleton took GMM out for its first big spin. The model says, we make sense of out of asset returns -- we should understand the large expected-return premium for holding stocks, and why that premium varies over time (we'll talk about that more in the upcoming Shiller post) -- by the statement that the expected excess return, discounted by marginal utility growth, should be zero
How do we take this to data? How do we find parameters beta and gamma that best fit the data? How do we check this over many different times and returns, to see if those two parameters can explain lots of facts? What do we do about that conditional expectation Et, conditional on information in people's heads? How do we bring in all the variables that seem to forecast returns over time (D/P) and across assets (value, size, etc.)? How do we handle the fact that return variance changes over time, and consumption growth may be autocorrelated?
When Hansen wrote, this was a big headache. No, suggested Lars. Just multiply by any variable z that you think forecasts returns or consumption, and take the unconditional average of this conditional average, and the model predicts that the unconditional average obeys
Lars worked out the statistics of this procedure -- how close should the other averages be to zero, and what's a good measure of the sample uncertainty in beta and gamma estimates -- taking in to account a wide variety of statistical problems you could encounter. The latter part and the proofs make the paper hard to read. When Lars says "general" Lars means General!
But using the procedure is actually quite simple and intuitive. All of econometrics comes down to a generalized version of the formula sigma/root T for standard errors of the mean. (I recommend my book "Asset Pricing" which explains how to use GMM in detail.)
Very cool.
The results were not that favorable to the consumption model. If you look hard, you can see the equity premium puzzle -- Lars and Ken needed huge gamma to fit the difference between stocks and bonds, but then couldn't fit the level of interest rates. But that led to an ongoing search -- do we have the right utility function? Are we measuring consumption correctly? And that is now bearing fruit.
GMM is really famous because of how it got used. We get to tests parts of the model without writing down the whole model. Economic models are quantiative parables, and we get to examine and test the important parts of the parable without getting lost in irrelevant details.
What do these words mean? Let me show you an example. The classic permanent income model is a special case of the above, with quadratic utility. If we model income y as an AR(1) with coefficient rho, then the permanent income model says consumption should follow a random walk with innovations equal to the change in the present value of future income:
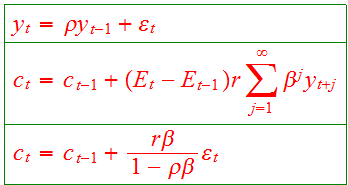
This is the simplest version of a "complete" model that I can write down. There are fundamental shocks, the epsilon; there is a production technology which says you can put income in the ground and earn a rate of return r, and there is an interesting prediction -- consumption smooths over the income shocks.
Now, here is the problem we faced before GMM. First, computing the solutions of this sort of thing for real models is hard, and most of the time we can't do it and have to go numerical. But just to understand whether we have some first-order way to digest the Fama-Shiller debate, we have to solve big hairy numerical models? Most of which is beside the point? The first equations I showed you were just about investors, and the debate is whether investors are being rational or not. To solve that, I have to worry about production technology and equilibrium?
Second, and far worse, suppose we want to estimate and test this model. If we follow the 1970s formal approach, we immediately have a problem. This model says that the change in consumption is perfectly correlated with income minus rho times last year's income. Notice the same error epsilon in both equations. I don't mean sort of equal, correlated, expected to be equal, I mean exactly and precisely equal, ex-post, data point for data point.
If you hand that model to any formal econometric method (maximum likelihood), it sends you home before you start. There is no perfect correlation in the data, for any parameter values. This model is rejected. Full stop.
Wait a minute, you want to say. I didn't mean this model is a complete perfect description of reality. I meant it is a good first approximation that captures important features of the data. And this correlation between income shocks and consumption shocks is certainly not an important prediction. I don't think income is really an AR(1), and most of all I think agents know more about their income than my simple AR(1). But I can't write that down, because I don't see all their information. Can't we just look at the consumption piece of this and worry about production technology some other day?
In this case, yes. Just look whether consumption follows a random walk. Run the change in consumption on a bunch of variables and see if they predict consumption. This is what Bob Hall did in his famous test, the first test of a part of a model that does not specify the whole model, and the first test that allows us to "condition down" and respect the fact that people have more information than we do. (Lars too walks on the shoulders of giants.) Taking the average of my first equation is the same idea, much generalized.
So the GMM approach allows you to look at a piece of a model -- the intertemporal consumption part, here -- without specifying the whole rest of the model -- production technology, shocks, information sets. It allows you to focus on the robust part of the quantitative parable -- consumption should not take big predictable movements -- and gloss over the parts that are unimportant approximations -- the perfect correlation between consumption and income changes. GMM is a tool for matching quantitative parables to data in a disciplined way.
This use of GMM is part of a large and, I think, very healthy trend in empirical macroeconomics and finance. Roughly at the same time, Kydland and Prescott started "calibrating" models rather than estimating them formally, in part for the same reasons. They wanted to focus on the "interesting" moments and not get distracted by the models' admitted abstractions and perfect correlations.
Formal statistics asks "can you prove that this model is not a 100% perfect representation of reality" The answer is often "yes," but on a silly basis. Formal statistics does not allow you to say "does this model captures some really important pieces of the picture?" Is the glass 90% full, even if we can prove it's missing the last 10%?
But we don't want to give up on statistics, which much of the calibration literature did. We want to pick parameters in an objective way that gives models their best shot. We want to measure how much uncertainty there is in those parameters. We want to know how precise our predictions for the "testing" moments are. GMM lets you do all these things. If you want to "calibrate" on the means (pick parameters by observations such as the mean consumption/GDP ratio, hours worked, etc.), then "test" on the variances (relative volatility of consumption and output, autocorrelation of output, etc.), GMM will let you do that. And it will tell you how much you really know about parameters (risk aversion, substitution elasticities, etc.) from those "means", how accurate your predictions about "variances" are, including the degrees of freedom chewed up in estimation!
In asset pricing, similar pathologies can happen. Formal testing will lead you to focus on strange portfolios, thousands of percent long some assets and thousands of percent short others. Well, those aren't "economically interesting." There are bid/ask spread, price pressure, short constraints and so on. So, let's force the model to pick parameters based on interesting, robust moments, and let's evaluate the model's performance on the actual assets we care about, not some wild massive long-short ("minimum variance") portfolio.
Fama long ran OLS regressions when econometricians said to run GLS, because OLS is more robust. GMM allows you to do just that sort of thing for any kind of model -- but then correct the standard errors!
In sum, GMM is a tool, a very flexible tool. It has let us learn what the data have to say, refine models, understand where they work and where they don't, emphasize the economic intuition, and break out of the straightjacket of "reject" or "don't reject," to a much more fruitful empirical style.
Of course, it's just a tool. There is no formal definition of an "economically interesting" moment, or a "robust" prediction. Well, you have to think, and read critically.
Looking hard but achieving a remarkable simplicity when you understand it is a key trait of Lars' work. GMM really is just applying sigma/Root T (generalized) to all the hard problems of econometrics. Once you make the brilliant step of recognizing they can be mapped to a sample mean. His "conditioning information" paper with Scott Richard took me years to digest. But once you understand L2, the central theorem of asset pricing is "to every plane there is an orthogonal line." Operators in continuous time, and his new work on robust control and recursive preference shares the same elegance.
The trouble with the Nobel is that it leads people to focus on the cited work. Yes, GMM is a classic. I got here in 1985 and everyone already knew it would win a Nobel some day. But don't let that fool you, the rest of the Lars portfolio is worth studying too. We will be learning from it for years to come. Maybe this will inspire me to write up a few more of his papers. If only he would stop writing them faster than I can digest them.
 |
| Source: Becker-Friedman Institute |
(This is a day late, because I thought I'd have to wait a few more years, so I didn't have a Hansen essay ready to go. Likewise Shiller, it will take a day or two. Thanks to Anonymous and Greg for reporting a typo in the equations.)
Update: I'm shutting down most comments on these posts. This week, let's congratulate the winners, and discuss issues again next week.